|
На первый взгляд, мысль о сопоставлении звукового строя языка с музыкальным звукорядом выглядит совершенно естественно: налицо единство материального носителя — звук, а значит, какие-то точки соприкосновения отыщутся наверняка. Обнадеживают и какие-то терминологические параллели: артикуляция, интонация, темп и ритм, акценты, сильные и слабые позиции — все это присутствует как в музыке, так и в лингвистике, и даже весьма похожим образом. Почему бы тогда не попытаться отыскать фонологические аналоги музыкальной звуковысотности?
Вульгарная теория музыки тут как тут. Про семь нот все слышали. И про семь цветов радуги. Сопоставление напрашивается. А тут еще и семь гласных греческого языка — ну какой же еще язык взять за исходный пункт европейской культуры? И дальше про семь планет, про чакры и минералы, про чудеса света и семь свободных искусств...
С другой стороны, из музыки легко выдрать систему из пяти звуков — пентатонику. И здесь сразу же вспоминаем про пятерку гласных испанского (или русского) языка, про синестезию Рембо, про пять континентов и китайскую астрологию. Наиболее продвинутые тут же смекнут про пять ступеней абляута.
Если серьезно, всю эту нумерологию следует направить чистой палочкой в помойное ведро и поискать реальных соответствий — как структурных (дискретные наборы фонем), так и динамических (сходные правила сочетаемости и голосоведения). А тут, на невооруженный взгляд, похожего мало. Звуки языка, в отличие от музыкальных тонов, не выстраиваются в один ряд по "высоте", они многомерны — и (по всей видимости) описываются большим количеством параметров. Тем более не заметно какой-либо периодичности — по аналогии с музыкальной октавой. Здесь даже близко нет чего-нибудь вроде обертонового ряда (из которого, в конечном счете, и происходят музыкальные звукоряды). Более того, мы даже не можем с уверенностью сказать, что входит в звуковой состав каждого конкретного языка: отличить варианты произнесения одного звука (аллофоны) от от качественно различных звучаний (фонем) иногда бывает весьма и весьма проблематично. Запись текста на бумаге фиксирует действительное звучание лишь приблизительно: скорее, слова как комбинации букв подобны иероглифам, заметкам, вроде узелков на память, — вызывающим правильный звуковой образ как ассоциацию у носителя языка. Поэтому во многих системах письма почти невозможно прочесть совершенно незнакомое слово, особенно в изолированном начертании, без контекста: — предположительно, в качестве гипотезы.
И все же: объективно человеку дан дискретный набор фонем, каждая из которых может существовать в огромном количестве вариантов — представляя, тем не менее, один и тот же звук. Как в музыке: ступень звукоряда есть некоторая зона, область высот, в пределах которой звук может варьироваться, оставаясь качественно тем же самым. Разные языки имеют свои наборы фонем — и это похоже на различие этнических звукорядов, или эволюцию музыкальных строев, задокументированную в истории музыки. Вот, например, из первых попавшихся под руку книжек [Новое в зарубежной лингвистике (1989); О. Семереньи, Введение в сравнительное языкознание (1980)]:
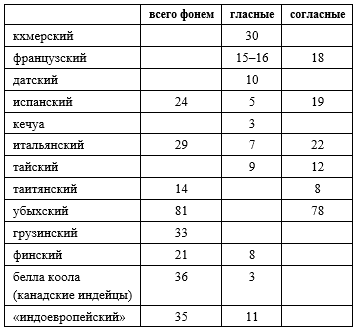
Для сколько-нибудь серьезного осмысления — данных маловато. Тем более, что принцип подсчета попахивает откровенным произволом. Особенно с согласными — которые от гласных не всегда просто отличить: всякие там сонорные, плавные и т. п. во многих языках играют слогообразующую роль — не переставая при этом быть согласными. Взять для примера хотя бы "полугласные" [й] или [ў], которые присутствуют практически во всех языках — кроме, быть может, совсем уж экзотических. Они частенько изображаются на письме теми же буквами, что и гласные [и], [у], — это откровенно выражает их двойственное восприятие носителями языка. Тем более, что принцип подсчета попахивает откровенным произволом. Особенно с согласными — которые от гласных не всегда просто отличить: всякие там сонорные, плавные и т. п. во многих языках играют слогообразующую роль — не переставая при этом быть согласными. Взять для примера хотя бы "полугласные" [й] или [ў], которые присутствуют практически во всех языках — кроме, быть может, совсем уж экзотических. Они частенько изображаются на письме теми же буквами, что и гласные [и], [у], — это откровенно выражает их двойственное восприятие носителями языка.
Составлять подобные таблицы без какой-нибудь теоретической идеи — дело совершенно ненаучное. Обработка наблюдений основана на весьма жестких предположениях о свойствах объекта, и параметры статистики в науке не берут с потолка, а выводят из абстрактной модели, пусть даже сугубо качественной, без математических наворотов.
Для ясности: дискретность набора фонем не имеет отношения к артикуляции. Поле всех возможных звучаний распадается на фонемы не потому, что мы что-то умеем делать разными органами — скорее, наоборот, эти самые органы вынуждены эволюционировать, подстраиваясь под общественную необходимость, выраженную в данном случае некоторой фонологической структурой. Одна и та же фонема разными людьми воспроизводится по-разному. Да, у некоторых она будет как-то странно окрашена — это называется акцентом, и само существование подобного понятия предполагает разнообразие форм. В конце концов, странность — дело относительное; все мы некоторым образом странные. А для речи важно только одно: чтобы понимали. Если вы можете задним проходом изобразить то, что обычно делается губами, — честь вам и хвала, уже можно по-человечески общаться. В современном мире, как известно, в большинстве случаев звук возникает не путем работы артикуляционных органов, а путем синтеза в электрических цепях (как минимум, путем считывания аудиозаписи с какого-нибудь материального носителя) и последующего озвучивания за счет вынужденных колебаний чего-то твердого. Так что, будем классифицировать фонемы по характеру движения диффузора? Точно так же, письменность постепенно сводится к клавиатуре. И уже поздно классифицировать графемы по характеру почерка или материалу типографских шрифтов... А скоро вообще перестанут писать — даже на клавиатуре. Прямо из мозга — в компьютер. И наоборот. Так что отличить одно от другого станет просто невозможно. Но, по счастью, и не нужно — ибо ни письменность, ни фонология от конкретной реализации практически не зависят.
Вовсе не факт, что какое-то подмножество фонем возможно линейно упорядочить; очень может оказаться, что язык, наоборот, подбирает базовые единицы по принципу качественного различия, так что набор базовых фонем связан с количеством измерений фонологического пространства, а вовсе не выстраиванием вдоль какого-то измерения (такое выстраивание будет соответствовать тогда отдаленности аллофона от базы, отклонению от "наиболее типичного" звучания. Нечто подобное исторически наблюдалось в ранней античности, где музыкальные тоны осознавались как самостоятельные и качественно различные (каждый со своим именем!), не объединяясь в единый звукоряд даже тогда, он совершенно определенно сформировался на практике. С другой стороны — пример с восприятием цвета, когда сложные цвета образуются смешением трех основных с соответствующими интенсивностями. "Базис" допустимо выбирать по-разному. Например, исходя из доступных типографских красителей (подобно тому, как физиология влияла на классификацию певческих голосов по звуковому охвату). Если идти от физики, каждый "простой" цвет сопоставляется с одним числом — частотой света (или длиной волны). На практике, конечно, базовые цвета отвечают довольно широким распределениям, и всем известное компьютерное пространство RGB спокойно уживается с фотометрическими стандартами наблюдательной астрономии (исходно связанными с различиями в спектральной чувствительности фотоэмульсий и фотоэлементов). Тут сразу приходят на ум гласные в языке, которые, вроде бы, отличаются друг от друга по формантному составу: три основных форманты определяют качество фонемы. Правда, соответствие получается с точностью "до наоборот"; однако, в принципе, ничто не мешает описывать цвета по фонологической схеме: не фиксировать частоты, меняя интенсивности, — а при одной интенсивности сдвигать частоты опорных цветов. Это очевидно ведет нас от трехцветной модели к любимой схеме профессиональных дизайнеров: тон — яркость — насыщенность. Идея проста: два оттенка красного дают красное, два оттенка голубого дают голубое — и любые линейные комбинации цветов допускают ту же арифметику, с охранением качества (окраски). Конечно, в разумных пределах.
Сплошные параллели — глаза разбегаются. На самом деле, скорее всего, в живом языке реализуются все мыслимые (и немыслимые) варианты: каждый в каких-то условиях доминирует в восприятии... Но вернемся все-таки к гласным. Так ли уж все многомерно в фонологическом царстве?
Теория звуковысотности в музыке выстраивает из качественно различных тонов особые структуры — звукоряды. С учетом иерархии возможных вложений одного звукоряда в другой, получается нечто более сложное — музыкальные строи. Звукоряды определяют набор возможных в каждом строе музыкальных интервалов. Но как все это связано с музыкой? Просто перечислить — это слишком мало, надо бы еще догадаться, чем один интервал отличается от другого, в разных контекстах. И здесь теория позаимствовала у фонологии понятие форманты как специфической характеристики звучания, не связанной с высотой голоса. Действительно, качество интервала в музыке мало зависит от его положения на шкале высот; точно так же, сдвиг основного тона при произнесении фонемы дает ту же самую фонему. Тут, впрочем, сходство заканчивается, и начинаются различия. Если обертоновый ряд музыкального тона сдвигается вместе с основным тоном — положение фонологических формант от высоты голоса никак не зависит, и никакой "обертоновости" тут, вроде бы, не прослеживается. Все, отбой?
Как бы не так. Теория звуковысотного восприятия утверждает, что музыкальный тон, помимо собственно физической высоты, характеризуется еще и так называемым "внутренним тембром", который и определяет качество звука, обладая отчетливо выраженной формантной структурой. С физическими характеристиками звучания внутренний тембр связан не напрямую, а через культурную традицию; но здесь мы лишь заметим, что относительная независимость формантного строения от высоты звукоизвлечения в музыке, оказывается, тоже есть — хотя и в несколько ином разрезе. Другими словами: музыкальный интервал — это не просто разность высот двух ступеней звукоряда, а еще и определенное качество, которое сохраняется при любом расположении интервала на шкале высот. В общем случае, сопоставляются не два звука, а больше (созвучия) — вплоть до звукоряда в целом, который также обладает особым, только ему присущим качественным своеобразием. Собственно, такое качество звука и называется словом "тембр".
Итак, говорить о фонемах как звуковысотных образованиях возможно в плане тембровой окраски — а простейший тембр предполагает устойчивую связь двух звучаний. Поскольку абстрактных точек в природе не бывает, звук всегда захватывает некоторую зону высот, а иногда сопоставляются целые звуковые пласты. Так мы возвращаемся к связи качества фонемы (пока говорим только о гласных) с взаимным расположением формант. Следовательно, должно быть некоторое отношение между формантами, которое и отвечает за качество звука. Что именно? У нас в распоряжении два параметра: базовая частота f и ширина Δf. Поскольку данные о ширинах формант в доступной лично мне литературе практически отсутствуют, остается ориентироваться на звуковысотное положение. Опять же, это ближе к нашим представлениям о музыке. Расстояния на шкале высот определяются логарифмами отношений частот; соответственно, искать намеки на "музыкальность" следует, анализируя, логарифмы частот, log f (обычно по основанию 2).
Прекрасно. Опять же, достаем с полки что под руку подвернулось — и начинаем оцифровывать графики и вычислять (ограничиваясь пока только первыми двумя формантами).
Б. Н. Головин, Введение в языкознание (1973), с. 39:
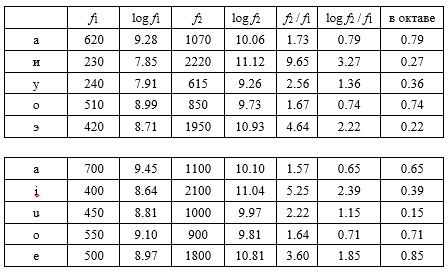
С. А. Гельфанд, Слух (1984), с. 323:
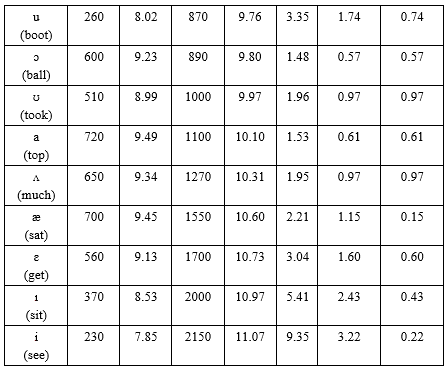
Гельфанд , с. 329:

Очевидно, данные неполны и далеко не точны. Точность оцифровки — до нескольких единиц последнего знака, и это способно существенно повлиять на выводы. Однако здесь наше дело оценить саму возможность выстраивания фонем в зонные шкалы, подобные звукорядам, — и копать глубже пока рано. С другой стороны, никакой эксперимент не существует сам по себе, он поставлен под определенную теоретическую идею и заточен на выявление того, что именно эта теория считает существенным. Если всплывут новые теоретические соображения, придется, как минимум, пересмотреть отношение к имеющимся данным — а потом целенаправленно заказывать экспериментаторам дополнительные измерения, с соответствующей модификацией методик и принципов интерпретации. Горы старых фактов никак не заменят эмпирической свежатинки.
Особый вопрос о межформантных расстояниях больше единицы. Двоичные логарифмы, по старой музыковедческой традиции, выбраны для того, чтобы уложить все ступени звукоряда в октаву, интервал между основным тоном и первой гармоникой. С некоторыми исключениями, октавность — это священная корова элементарной теории музыки; неоктавность некоторых "искусственных" ладов преподносится именно как признак искусственности. Но играет ли октава такую же роль в фонологии? Если да — можно смело отбрасывать целую часть и рассматривать положения ступеней в пределах октавы. Если нет — придется искать другие принципы оценки. Наглым произволом, для определенности, положим, что какой-то аналог октавности музыкальных звукорядов в фонологии тоже есть — хотя механизм ее возникновения может быть совершенно иным. В конце концов, и в музыке неэлементарная теория предсказывает естественные отклонения от октавности — хотя обычно весьма слабые.
В итоге — нечто вроде фонологических "звукорядов", в сопоставлении с "натуральными" интервалами и ступенями обычного 12-ступенного "хорошо темперированного" строя:
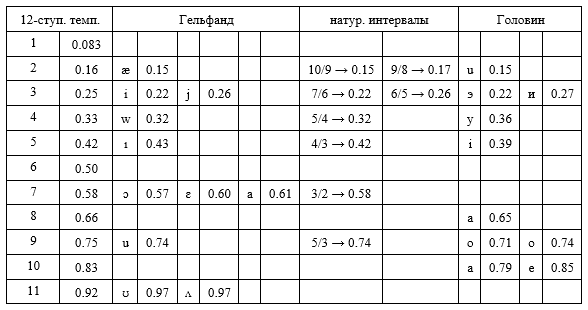
С одной стороны, картина получилась довольно определенная: гласные, похоже, все-таки возможно соотнести с музыкальными интервалами (простейшими созвучиями, с выраженной тембровой окраской). В качестве чисто эмпирического курьеза — очевидное избегание интервала в половину октавы, сложности с представлением септимы и узких интервалов, различие терций. Прямо как в музыке.
Однако заметно, что данные Головина не очень соответствуют книге Гельфанда и хуже ложатся на 12-ступенную темперацию. Различия в трактовке фонем ожидаемы: русские воспринимают их не так, как американцы (а американцы не так, как англичане). Формирование 12-ступенной шкалы — итог длительного развития, и далеко не факт, что фонологические системы естественных языков уже ушли от пентатоники и диатоники (или, допустим, каких-нибудь модальных систем).
И тут начинается полет фантазии, поток тем для обсуждения...
Прежде всего встает вопрос о границах вариативности. Музыкальные звукоряды — это зонные структуры; благодаря этому оказывается возможным выразительное интонирование и ансамблевое исполнение, объединяющее инструменты (голоса) с разной настройкой. Точно так же, можно заранее предположить, что и для фонологических шкал существуют объективно возникающие границы зон. В связи с этим было бы интересно проследить зависимость формант от индивидуальных особенностей, интонаций и прочих обстоятельств речи. Например, если гласные не произносить, а петь (особенно профессионально поставленным голосом), — что-то изменится или нет? Известно, что китайские тоны по-разному интонируются в разных условиях, в зависимости от общей динамики речевого потока. По всей вероятности, в европейских гласных тональная архаика редуцирована — но не исчезла вовсе (учитывая, например, явления вроде абляута); окраска гласной существенно зависит от того, что идет до или после. Но если мы начинаем "держать ноту", удлиняем собственно голосовую часть по сравнению с переходными процессами, единая фонема может запросто развалиться на несколько, с восстановлением ранее свернутой "внутренней" интонации — по-разному у разных народов. В перспективе это может стать неплохим инструментом сравнительной лингвистики и истории языка.
Из той же серии вопрос о произношении в ударной и безударной позиции (для языков без ярко выраженного ударения можно говорить о сильных и слабых позициях внутри синтагмы или фразы). Здесь меняется не только количество, но и качество звука. Традиционная фонология предпочитает говорить о чередовании фонем — но в рамках зонной теории возможна иная интерпретация: вариации в пределах зоны или переход от базовой шкалы к вложениям.
Далее, есть соблазн трактовать дифтонги подобно аккордам в музыке; тогда, очевидно, не всякие сочетания звучат "гармонично" — причем представление о "гармоничности" зависит от используемой шкалы (фонологического "звукоряда"). Типично: гласная [e/o/a] + i, гласная + u (и наоборот). А в иранских языках [e/o/a] вообще сливаются в одну гласную [a]; это намек на их родство внутри шкалы, существование достаточно широкой зоны в одном из вложений, охватывающей все эти "аллофоны". По данным из Гельфанда: [ɔ ɛ a] живут где-то в районе 7 ступени темперированной шкалы, тогда как [i] — 3 ступень, [w] — 4 ступень. Соответственно, [ɔ ɛ a] — [i] есть фонологический аналог большой терции, а [ɔ ɛ a] — [w] дает малую терцию. Тут напрашиваются далеко идущие ассоциации с историей мажора и минора в европейской музыке: дифтонги с [i] в языках представлены шире и выглядят как-то "активнее".
Возвращаясь к "внутренностям" и "границам", мы опять поднимаем вопрос о различении гласных и согласных. Согласные, как известно, бывают всякие. Например, есть такие, которые запросто можно петь, затягивать до бесконечности — в этом совершенно подобны гласным (а в каких-то языках так и употребляются). Здесь, вероятно, есть свои шкалы, устроенные все по тому же зонно-иерархическому принципу. Будут они учитываться наряду с гласными или образуют свои, ортогональные измерения — вопрос открыт. Наверняка это зависит от конкретного языка, и звуковой строй определяется, помимо всего прочего, также и соотношением голосовых и шумовых шкал.
Однако есть и согласные другого типа (взрывные), петь которые, мягко выражаясь, не всякий сможет. Это типичные переходные процессы, маркеры, отделяющие в речевом потоке одну "ноту" от другой (или одно "созвучие" от другого). В частности, так речь отделяется от молчания. Возможны ли "звукоряды" в этой фонологии? Учитывая универсальность зонных структур — безусловно. Только с формантным составом это может иметь мало общего. Хотя — кто знает? Где-то в глубине вдруг откопает кто-то совершенно те же явления... В конце концов, человеческое восприятие универсальным образом организовано — и не зависит от физиологии, это совсем другой уровень.
С учетом "звукорядов" согласных, соединение их с гласными оказывается вполне подобно тем же дифтонгам (и трифтонгам). Особенно это заметно по отношению к "певучим" согласным (мычашим, ноющим, текущим, шипящим, свистящим, ржащим и чирикающим), которые явно влияют на качество соседних гласных, как бы подключая разные регистры, подчеркивая те или иные группы гармоник. С этим может быть связана возможность переноса гласной из одной октавы в другую (разумеется, пока на уровне метафоры): интуитивно, назальность делает фонему в целом "ниже" (не по абсолютной высоте, а по соотношению формант); закрытые гласные в целом "выше" более открытых и т. д. Тогда получается, что фонологическое качество относится не только (и не столько) к отдельным фонемам, но и к их "комплексам", фонологическим "созвучиям". Базовой единицей речи оказывается не фонема, а "слог" — и разделить его на фонемы возможно только в некоторых отношениях и далеко не всегда.
Кстати оказывается, что и согласные с согласными соединяются по тому же принципу, и точно так же влияют на качество друг друга. Двойственность фонем: иногда это особое звучание, иногда модификатор для другой фонем... Что очень даже напоминает дуализм мелодики и гармонии в музыке. В частности, типичные последовательности фонем вызывают мысль об универсальности попевочных систем, некоторые из которых впоследствии перерастают в более развитые звукоряды. Не с этим ли связано единообразие морфем, и формообразования вообще, в индоевропейских языках?
В этой карусели поверхностных аналогий есть и вопрос об октаве и унисоне как особых фонологических интервалах. Для унисона — первая и вторая форманты сливаются. Возможно? Возможно. Например, как у шипящих. В музыке унисон — это вовсе не тождество, ибо звуки одинаковой высоты могут различаться по другим признакам. Точно так же, фонологический "унисон" может отвечать разнообразным созвучиям (так, в японском языке совпадают [r] и [l], а немцы вовсе не случайно обозначают два, казалось бы, очень разных звука одной и той же комбинацией букв ch). В каком-то смысле это нечто нейтральное, теряющее свою собственную окраску и сливающееся с окружением — своего рода шва. Но сюда же примыкают и случаи поглощения нескольких фонем одной "суперфонемой" (зоной одного из вложений) — например, гласные в безударной позиции. Заметим, что (как и в музыке) слабое отклонение от унисона воспринимается на слух очень напряженно, как резкий диссонанс; таковы (как видно из таблицы) "вводные" тона [ʊ] и [ʌ]. С другой стороны, интервал октавы возникает между "почти" одинаковыми тонами — хотя разность высот здесь бросается в уши. Нечто подобное наблюдается и в языке: сравните [m] и [ɱ], [n] и [ŋ] — в конце концов, и [m] c [n] вполне могут оказаться вариантами одной ступени фонологической шкалы.
Но возможен и другой пучок аналогий. В качестве противовеса и дополнения.
В музыке спектр звука отвечает не только за высоту — есть еще и низкочастотная составляющая (темп и ритм), и общая модуляция — музыкальный тембр. Нота одной высоты может исполняться в разных тембрах, а в некоторых случаях оркестровка не менее важна, чем мелодия или гармония. Восприятие умеет разделить эти стороны единого звучания (для этого оно и развивается) — так что во внутреннем представлении они относительно независимы (хотя в любом случае исторически складывается некоторая зонная структура).
Точно так же и в речи: есть фонологическое качество — а есть окраска, речевые варианты. Тембр и темп голоса обладают собственной выразительностью. И это язык всячески использует. Например, когда люди передают чужие слова, они особым образом меняют голос — не для того, чтобы изобразить чью-то манеру, а для того, чтобы выразить свое к ней отношение. Мультики вообще иногда обходятся чистой интонацией.
Согласные в слоге — меняют тембр гласных. И это вполне соотносится с оркестровкой, или цветом (фактурой) в живописи. Даже если речь строить из одних гласных — придется разделять их в речевом потоке паузами (а значит, придыханиями, особыми согласными) или динамикой голоса (а согласные, собственно, и есть эта динамика).
Но разные стороны целостного звучания лишь относительно независимы. Соседство с согласными, вообще говоря, меняет гласные и в "высотном" отношении. Например, в русских слогах а, ба, та, ка — гласная [а] звучит очень по-разному. Требуются тысячелетия развития и особое воспитание, чтобы абстрагироваться от "инициали" и ощутить "рифму". Опыт поэзии тут не ради словца: способы стихосложения выявляют (хотя и с некоторым запозданием) реалии восприятия речи в каждую историческую эпоху. Даже сегодня слова "душа", "труба" и "ждала" для русского читателя как-то не в рифму (хотя для китайца тут прекрасный ассонанс). Для простых смертных (не имеющих языковедческого диплома) ка звучит явственно "выше", чем ба. Почему?
Когда в фонологическом эксперименте при произнесении разных слогов наблюдается та же формантная картина для той же гласной — это, скорее всего, артефакт, связанный с особыми условиями произнесения. Изолированные слоги артикулируются не так, как встроенные в поток речи, а неизбежная "лабораторная" задержка есть, фактически, уход от "окрашенной" гласной к изолированной, искусственное "отсечение" якобы несущественных переходных процессов. Тогда как на самом деле интерес представляют как раз начальные участки записей, с быстрыми переходами формант. Но здесь у меня данных совсем нет — кроме нескольких занимательных картинок из Гельфанда.
Если предположить, что окружение согласных способно менять "высоту" гласной без изменения фонемы — остаются разные варианты. Простейший случай — перенос в другую октаву (разведение формант). Но гораздо вероятнее сопоставление зон из разных вложений — нечто вроде знаков альтерации. Тогда оказывается, что развитость системы согласных в языке соотносится со строением соответствующего "звукоряда": чем больше согласных, тем больше ступеней (зон) базовой шкалы. Соответственно, вступает в действие и объективное ограничение на возможное количество ступеней (не больше нескольких десятков); это означает, что примеры из популярных книжек с сотнями различимых фонем — показатель чьего-то недопонимания. Впрочем, в музыке восприятие до сих пор не доросло до шкал более развитых, чем 12-ступенный темперированный строй; это не мешает существованию незамкнутых этнических модальных систем, в которых ноты вообще никто не считает — их может быть сколько угодно. Дело в том, что такая музыка реально опирается на звукоряд с относительно небольшим числом зон — однако устроен этот звукоряд по-особому: он допускает параллельное существование каких угодно звуковысотных вариантов и устанавливает правила перехода между ними. Точно так же и в языке возможны ладово неустойчивые (модальные) шкалы — отсюда кажущееся изобилие фонем в некоторых языках. Разные функции одной и той же ступени (фонемы) проявляются в разных обстоятельствах по-разному, порождая собственно аллофонию, многовариантность.
|



